A Quick Guide: How to Use Emote Portrait Alive
A technology named Emote Portrait Alive (EMO) is an AI game changer in the field of video creation. This program by Alibaba can help people create lively and realistic videos with just one picture and a sound clip.
With this unique feature, you can animate simple still photographs, transforming them into exciting videos where the image seems to be speaking or singing with real facial movements and nods.
Catalogs:
Part 1: What is Emote Portrait Alive?
The research carried out by Alibaba’s Institute for Intelligent Computing took place at its cutting-edge premises, leading to EMO. This pioneer institution plays a leading role in changing AI, and EMO is evidence of the milestone work done by its great team of researchers.
It was led by scientists including Linrui Tian, Qi Wang, Bang Zhang, and Liefeng Bo, who are famous in the artificial intelligence field.
To bridge the gap between static images and dynamic visual content, the EMO was aimed at creating technology that could produce more lifelike, expressive portrait videos. For this reason, there was an attempt to utilize the power of Artificial Intelligence (AI) to bring ‘life’ into photographs, thereby immersing the audience in them.
Part 2: Understanding the Technology and Method
Overview and Purpose of Emote Portrait Alive
The purpose of this technology is to make a voice-driven picture generation system that can produce an individual-facing digital video from a single reference image and voice audio (such as talking or singing). This video will consist of the subject’s head with expressive faces and different angles of the head that blend flawlessly into the audio inputted.
The sheer potency of EMO comes in its ability to create any length of video, constrained only by the time limits imposed by the audio file. This flexibility allows for various applications, including personalized video messages and social media content, as well as more complex ones, such as digital art, online education, and remote communications, among others.
Unique Audio-to-Video Synthesis Approach
What makes EMO different from traditional video generation techniques is one of its innovations, the direct audio-to-video synthesis approach. Instead of creating 3D models or face landmarks and so on as stage between, EMO totally skips these.
This method allows EMO to capture the subtle nuances and distinctive peculiarities that are often associated with natural speech and expressions.
In this way, by directly linking sound input to visual output, precise motions and peculiarities of each person’s pronunciation or facial expression can be presented in EMO. This level of detail and precision is vital in making videos that look real and genuine.
Employed Diffusion Model
At the core of EMO’s amazing capacity to generate videos is a powerful diffusion model. One of the most notable aspects that have led to diffusion models becoming so popular is their ability to produce extremely realistic synthetic images. In the case of EMO, this diffusion model was trained meticulously using an extensive dataset comprising over 250 hours of talking-head videos.
The set was carefully assembled from various sources such as speeches, movies, tv shows, and singing performances. Through this diverse range of visual data presented to it, EMO could appreciate complex intricacies in human facial expressions and head movements.
Frame Encoding and Diffusion Process
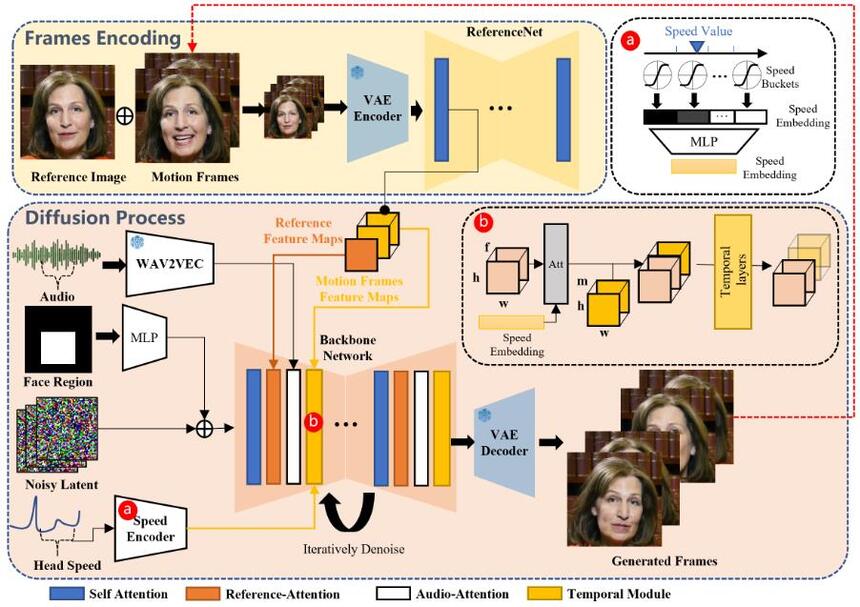
It must be borne in mind that making a video with EMO is a complex process. In the first step called Frames Encoding, ReferenceNet, which is a part of the neural network, extracts important features from the reference image and motion frames. This way, it ensures that the subject’s unique identity and characteristics are retained in the generated video.
The second stage referred to as the Diffusion Process uses an audio encoder that has been pre-trained to process supplied audio input and generate an audio embedding capturing both acoustic and linguistic information within an audio signal; this embedding plays a key role in driving subsequent processes of video generation.
In EMO, facial imagery generation is controlled by integrating multi-frame noise with facial region mask from reference image. It is this noise that provides a starting point for the diffusion model to repeatedly refine towards desired video frames.
Functionality of Multifaceted Tools
EMO is characterized by a remarkable ability to use different languages in songs, thus painting various portraits with the same skill. Tonal differences and subtleties are captured by the system in real-time, allowing the creative generation of avatars whose emotional content is as true to sound as possible.
EMO does not simply limit an avatar’s expressions and movements of the head to mere lip-synching but captures even tiny details in audio input meaning that the generated video corresponds to the emotions and intricacies inherent in audio.
Part 3: How to Use Emote Portrait Alive?
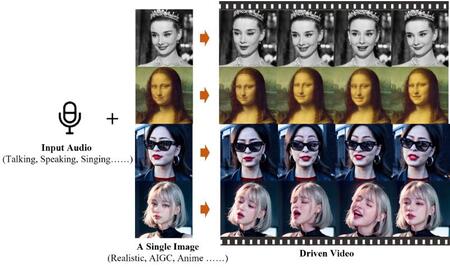
To use Emote Portrait Alive is a simple procedure that just needs two main things; one starting photo and the audio clip that can either be speech or song.
When you have these things, EMO’s algorithms become active and produce talented vocal avatars in videos that appear to be really there with alive faces and heads making various poses throughout the video that are perfectly synchronized with every word uttered.
The best thing about EMO is that it can make videos of any length as determined by the audio provided. This flexibility allows users to create videos from being short clips to long series depending on their purpose.
Part 4: Practical Applications & Implications
Real-world Application of Emote Portrait Alive
The real-world application of Emote Portrait Alive is inherent, diverse, and abundant in nature and spans both personal and professional domains. On a personal level, EMO can be used to create special birthday wishes or heartfelt messages for loved ones, at these cherished moments making the latter more personalized and engaging.
Animated Features Produced
One of the best parts of EMO software is its capacity to generate movies with natural expressions as well as dynamic head movements. With highly refined algorithms, this technology can capture every little sound variation in the audio input to create lifelike facial animations that are expressive.
Generating Expressive Videos of Arbitrary Length
EMO has another significant advantage which lies in its ability to produce expressive videos of any length as long as the input audio lasts. This makes it possible for users to generate customized videos that meet their specific requirements, whether it’s a short one for social media or an extensive one for other types of presentations or performances.
Accomplishments and Comparative Advantages
Emote Portrait Alive represents a big step forward in the realm of AI-powered video production. Substantive assessments and contrasts show that EMO is significantly better than prevailing state-of-the-art approaches in several metrics including video quality, identity preservation, and expressiveness.
EMO has shown to be the best alternative through a number of head-to-head comparisons with other established techniques such as DreamTalk, Wav2Lip, and SadTalker which it surpasses in terms of producing high-quality videos that are expressive and visually captivating.
Ethical Considerations
However, despite its exciting possibilities and potential applications Emote Portrait Alive raises ethical concerns due to its massive power. One main concern revolves around the possible misuse of EMO for impersonation without consent or dissemination of misinformation or harmful content.
Conclusion
Alive Emote Portrait is the epitome of a breakthrough in artificial intelligence that showcases how AI can change the way we create and view visual content. It enables users to create emotionally-powered and animated videos of static images while using one audio file, thus expanding creativity’s horizons to personal, artistic, and professional domains.
It uses an advanced diffusion model combined with its unique audio-to-video synthesis method to capture even the finest intricacies of human speech and expressions making them look visually stunning as well as genuinely reflecting upon the emotional depth and complexity of the sound input.
You Might Also Like
- Sora VS Runway Gen-2: Which is Better?
- Top 5 Text-To-Video AI Generators (2026 Newest)
- How to Use Claude 3 AI Chatbot: A Comprehensive Guide to Mastering the Anthropic Claude API
- An In-Depth Evaluation of Memory Capacities in Claude3 and GPT4
- Everything about Google Lumiere AI Text to Video [2026 Updated]

Tenorshare AI PDF: Chat, Summarize Insights from PDFs
Summarize complex PDFs in one click!Tenorshare AI PDF, Instant Summary
Summarize and chat with any PDF.
Tenorshare AI PDF: Chat, Summarize Insights from PDFs